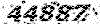جنبش دانش آزاد کامپیوتر
در این وبلاگ سعی داریم تا دایره المعارفی از مفاهیم و تکنولوژی های کامپیوتر را گردآوری کنیم و در اختیار همه قرار دهیم.جنبش دانش آزاد کامپیوتر
در این وبلاگ سعی داریم تا دایره المعارفی از مفاهیم و تکنولوژی های کامپیوتر را گردآوری کنیم و در اختیار همه قرار دهیم.خوشه بندی با Partial Supervision چیست؟

معمولا از خوشه بندی فازی برای یافتن ساختار در داده ها یی استفاده می شود که برچسب گذاری نشده اند. در این حالت سعی می شود که با قراردادن داده ها در خوشه های مختلف تابع هدفی به دست آید که مینیموم مقدار را دارا باشد. این روش ساختارها را برای ما مشخص می کند. قبلا گفته بودیم که با انتخاب توابع فاصله ی مختلف می توان جستجو در ساختارها را به شکلهای هندسی از خوشه ها متمرکز کرد. در این قسمت ایده ی نظارت جزئی را می پرورانیم که در آن زیر مجموعه ای از داده ها برچسب گذاری شده اند و این زیر مجموعه ها خوشه بندی سایر داده ها را هدایت می کنند.
خوشه بندی فازی با نظارت جزئی، درگیر زیرمجموعه ای از داده هاست که دارای بر چسب هستند. مخلوطی از داده های برچسب گذاری شده و بدون برچسب در بسیاری از شرایط دیده شده اند.
مجموعهای از کاراکترهای عددی با دست خط های مختلف را در نظر بگیرید. می خواهیم آنها را دسته بندی کنیم. خوشه بندی در دسته بندی آن ها بسیار مفید است. از آنجا که کاراکترها بدون برچسب هستند از روش یادگیری بدون نظارتUnsupervised Learning استفاده می کنیم. حال فرض کنید که یکسری اطلاعات به دست آوریم و یک زیر مجموعه ی کوچک از داده های برچسب گذاری شده ایجاد می کنیم . این کارکتر ها توسط یک متخصص برچسب گذاری شده اند. چنین کارکترها ی برچسب گذاری شده نقش مهمی در خوشه بندی ایفا می کنند. در واقع آنها به عنوان یک لنگرگاه برای خوشه ها هستند. در عمل فقط تعداد محدودی از داده ها را می توان بر چسب گذاری کرد. برچسب گذاری کاری هزینه بردار است و بهتر است قبل از هر کاری بررسی کنیم که بر چسب گذاری چه میزان در نتیجه خوشه بندی مفید است .
نظارت جزیی با توجه به میزان داده هایی که برچسب گذاری شده اند درجات مختلفی دارد . در واقع نظارت جزیی بین دو محدوده ی یادگیری بدون نظارت و یادگیری با نظارت قرار دارد. در یادگیری بدون نظارت داده ها فاقد برچسب هستند ولی در یادگیری با نظارت همه ی داده ها بر چسب دارند . شکل حدودی آن در شکل آمده است . در نظارت جزیی مخلوطی از داده ها ی برچسب گذاری شده و بدون برچسب وجود دارد .